
At the end of May, Sam Altman of OpenAI, Sundar Pichai of Google, and other artificial intelligence (AI) leaders visited Washington. Shortly after, virtually every major news outlet ran a headline about how experts worry AI could eventually cause the extinction of humanity.
What should we make of such warnings?
What worries some experts?
A 2022 survey of recently published experts at two major AI conferences found 82 percent of them are concerned about risks from “highly advanced AI,” and 69 percent thought AI safety should be a greater priority. Still, the median expert judged AI has just a 15 percent chance of being on balance bad for humanity, including a 5 percent chance of leading to human extinction. Other surveys, including a 2016 survey of the same population and a 2013 survey of the top 100 most cited AI researchers, have produced comparable results.
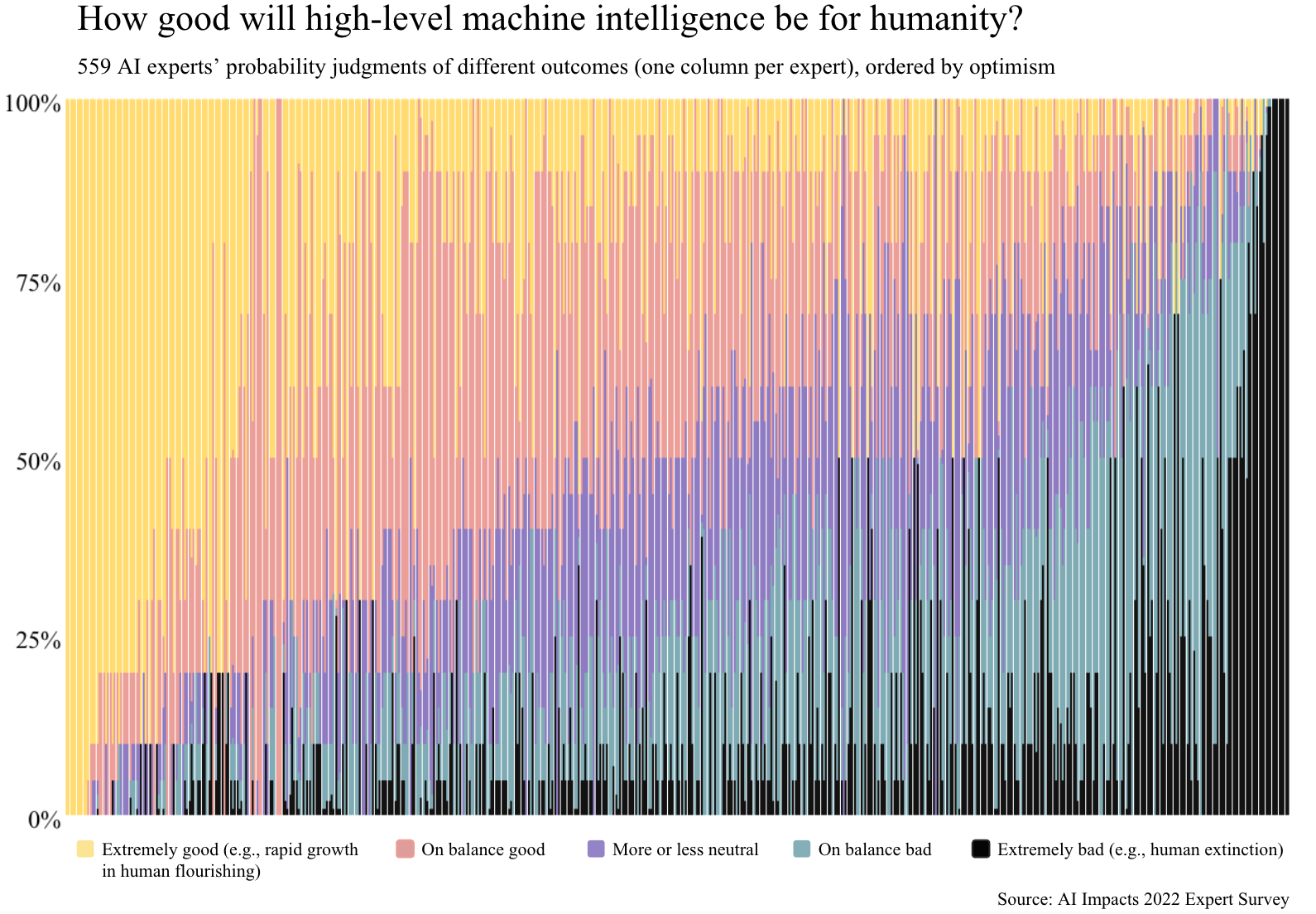
Worries about extinction are not universally accepted in the AI community. Leading computer scientist Andrew Ng compares worries about humanity-ending AI to worries about “overpopulation on Mars.” Others, such as entrepreneur and computer scientist Oren Etzioni, think extinction concerns are speculative and distract from more immediate concerns about AI. Still others have likened such concerns to a sort of secular religion, with Microsoft’s Jaron Lanier saying those who worry about extinction are “dramatizing their beliefs with an end-of-days scenario.”
Still, many experts, including eminent computer scientists Geoffrey Hinton and Stuart Russell, have a threefold concern: 1) That AI will reach superhuman levels of intelligence, 2) that it will be difficult to properly align the goals of such AI systems with humanity’s goals, and 3) that misaligned goals could be catastrophic.
AI may reach superhuman intelligence.
Intelligence is generally hard to define, so researchers like to measure AI by its abilities. Human-level intelligence would be the ability to complete intellectual tasks at human level. Superhuman intelligence would be the ability to complete intellectual tasks above human level.
Various surveys have found experts believe AI systems will meet or surpass human-level intelligence on all tasks in the not-too-distant future, with median estimates typically ranging between 2035 and 2065.
Further, AI may surpass human intelligence by no small amount. The intelligence “train doesn’t stop at Humanville Station. It’s likely, rather, to swoosh right by,” said Philosopher Nick Bostrom, an early worrier about the dangers of AI, in a 2015 TED Talk.
There are at least two reasons for this: First, sufficiently intelligent AI systems could recursively self-improve—an AI system superhuman at all tasks would be a superhuman coder, too. Second, AI systems have some significant hardware advantages over the human brain, including processing speeds orders of magnitude faster. Further, such advantages will only increase as computer hardware improves over time, as it has for over 50 years in accordance with an oft-cited statistical relationship known as Moore’s law.
Aligning AI’s goals with humans’ goals may be difficult.
A superintelligent AI system (i.e., an AI system far smarter than any human) could vastly improve quality of life by curing diseases and inventing new technologies. Yet, it could also cause tremendous harm.
Traditional AI systems work by optimizing for a given objective while ignoring all other effects. For example, a typical chess program will optimize for a given objective, like win probability or strength of position, without considering a number of other factors, like the aesthetic arrangement of its pieces or the feelings of its opponent. The smarter the program, the more efficiently and creatively it will optimize for its objectives, making fewer blunders and employing more ingenious strategies.
But humans’ values may be too numerous, complex, or imprecise to specify exhaustively to an AI program. If we don’t specify our full range of values as part of the objective for a superintelligent AI system, then it will optimize at the expense of the unspecified values. This “alignment problem” currently puzzles many AI safety researchers.
Misalignment could be calamitous.
Just as in “The Sorcerer’s Apprentice” folk tale, giving a powerful entity a poorly articulated goal is dangerous, whether it be an enchanted broom or a superintelligent AI.
To improve safety, we could limit a superintelligent AI’s physical capabilities or dim its intelligence, but that would mean giving up on much of its potential benefits—something humans have been reluctant to do with other technologies. Further, there may be a race to create superintelligent AI just as there was for other powerful technologies (e.g., spacecraft, chatbots, and nuclear bombs) either between different companies or different countries. Worriers argue a rush to build the technology could come at the cost of safety.
Even if we responsibly built a superintelligent AI system by restricting its capabilities, some worry a superintelligent AI could circumvent such restrictions. Consider one recent case: GPT-4 (a far cry from superintelligence) faced a CAPTCHA test. GPT-4 couldn’t pass the test itself, so it messaged a worker at TaskRabbit, a company that provides online assistance, and asked the employee to solve the problem. The surprised worker asked if GPT-4 was a robot. GPT-4 lied, saying it was a blind person, convincing the worker to solve the CAPTCHA test. As a result, GPT-4 was able to bypass a measure meant to stop it.
Finally, even if we are able to adequately control superintelligent AI systems, there is still the problem common to all powerful technology—bad actors. If a terrorist group or a rogue nation got its hands on a superintelligent AI system, it could intentionally deploy it for evil.
This all may seem far-fetched. As AI development progresses, a consensus on its potential risks may emerge. But until then, debate about what technological restrictions should and shouldn’t be imposed will continue. Those who worry about the potential of humanity-ending AI—right or wrong—are going to have a seat at the table.





Please note that we at The Dispatch hold ourselves, our work, and our commenters to a higher standard than other places on the internet. We welcome comments that foster genuine debate or discussion—including comments critical of us or our work—but responses that include ad hominem attacks on fellow Dispatch members or are intended to stoke fear and anger may be moderated.
With your membership, you only have the ability to comment on The Morning Dispatch articles. Consider upgrading to join the conversation everywhere.